air-quality-analysis
Jupyter notebooks and Python code for analyzing air quality (fine particles, PM2.5)
Table of contents
1. Basic data visualization
2. Correlation of PM2.5
2.1 Correlation of PM2.5 with time
2.2. Correlation of PM2.5 with wind and temperature (data cleaning)
2.2. Correlation with wind and temperature (analysis)
2.3 Correlation with MERRA-2 data
2.4 Conversion wind (U,V) component, RH from temperatures
3.1 Data selection
3.2 Regression
TODO
Tool and packages
4. Credits
PDF version is in PDF folder, likewise HTML’s
1. Basic data visualization
- introduce to basic setup of folder, install
pandas,matplotlib,seaborn(usingpipfor Python package),Anacondais a good choice if you are using Windows (or even Mac, Linux). Alternatively, try out Google Colaboratory - basic use of those tools (clean, explore, plot, interpret)
- work with a CSV file from Airnow.gov
- here are some graphs produced from this exercise
- basic line chart
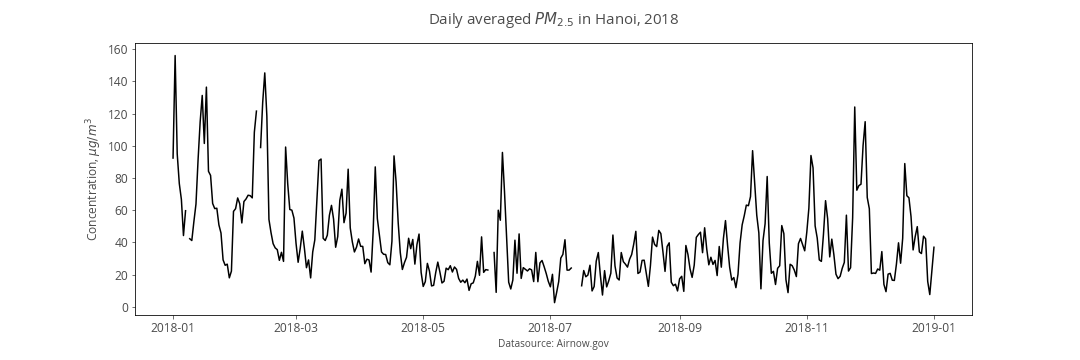
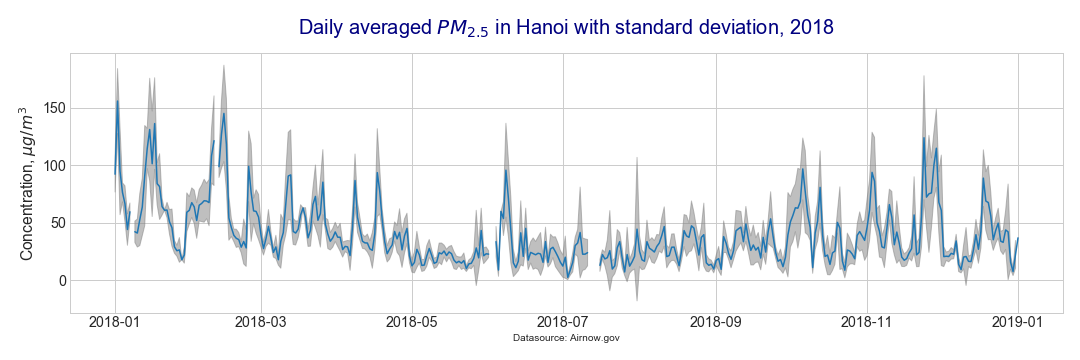
- line chart with a band for standard deviation
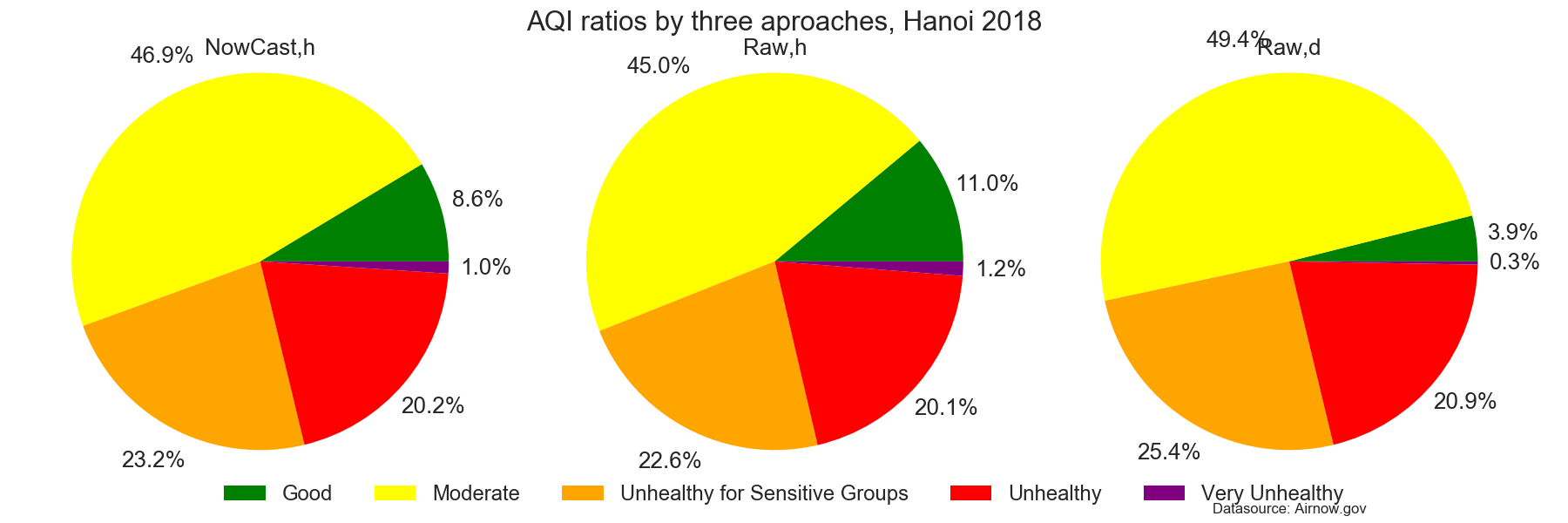
- pie chart with Air Quality Index (AQI)
2. Correlation of PM2.5
2.1 Correlation of PM2.5 with time
- continue to work with the .CSV file from AirNow.Gov to explore the correlation between PM2.5 and time such as:
- peak-traffic hours vs. non-peak traffic hours
- weekends vs. weekdays
- variation of each months
- here is some graphs produced from this exercise
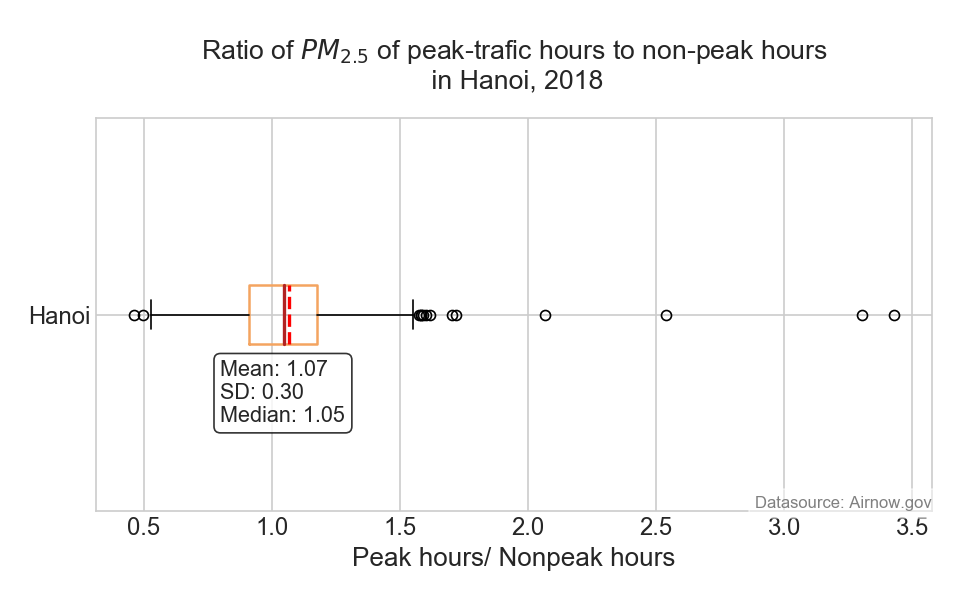
- a summary graph of this dataset
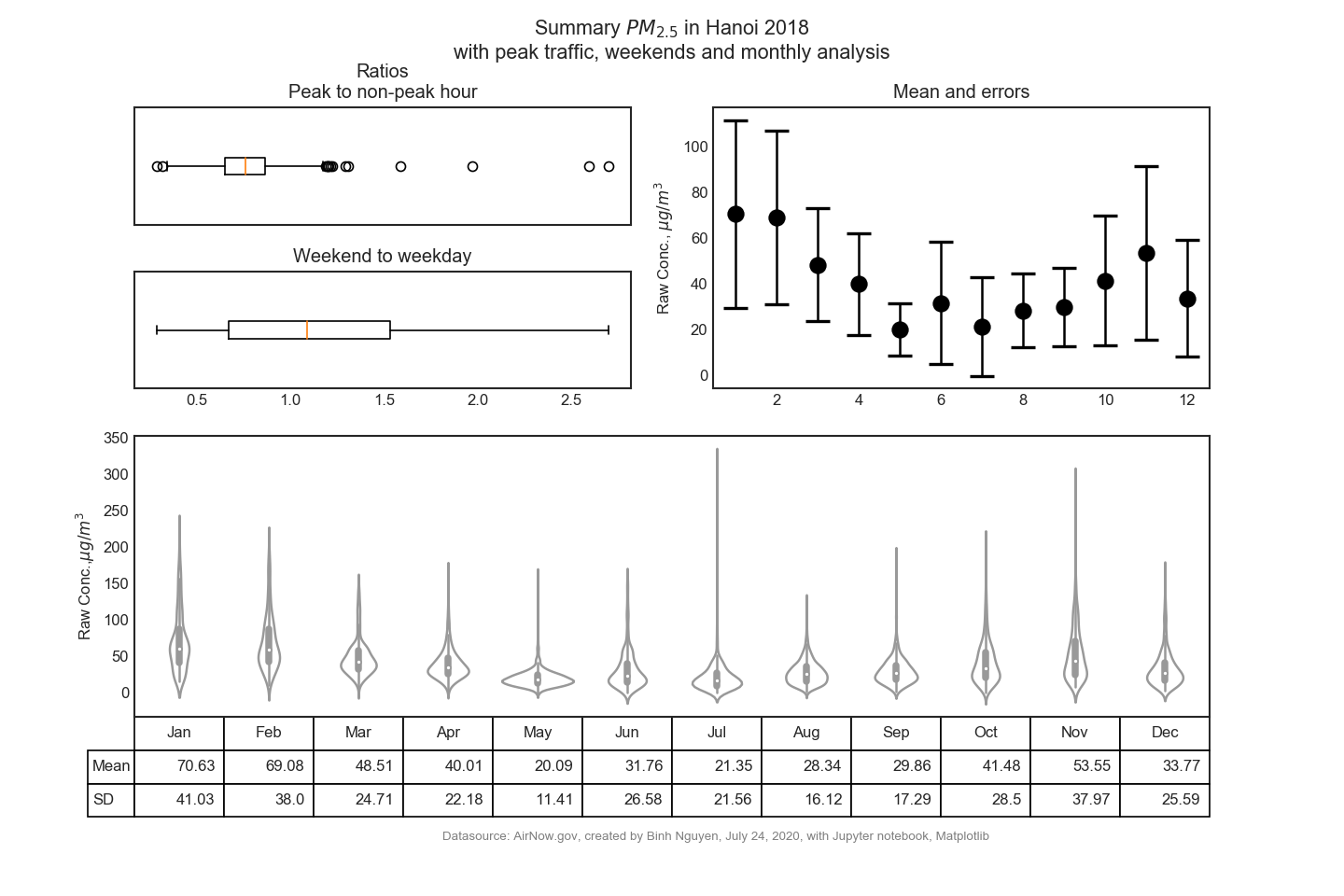
2.2 Correlation of PM2.5 with wind and temperature (data cleaning)
- explore data source (specifically working with archieved meteorologcal data from NOAA.GOV
- clean the data (which is formatted with Integrated Surface Data (ISD) style)
-
use
windrosepackage to make windrose plot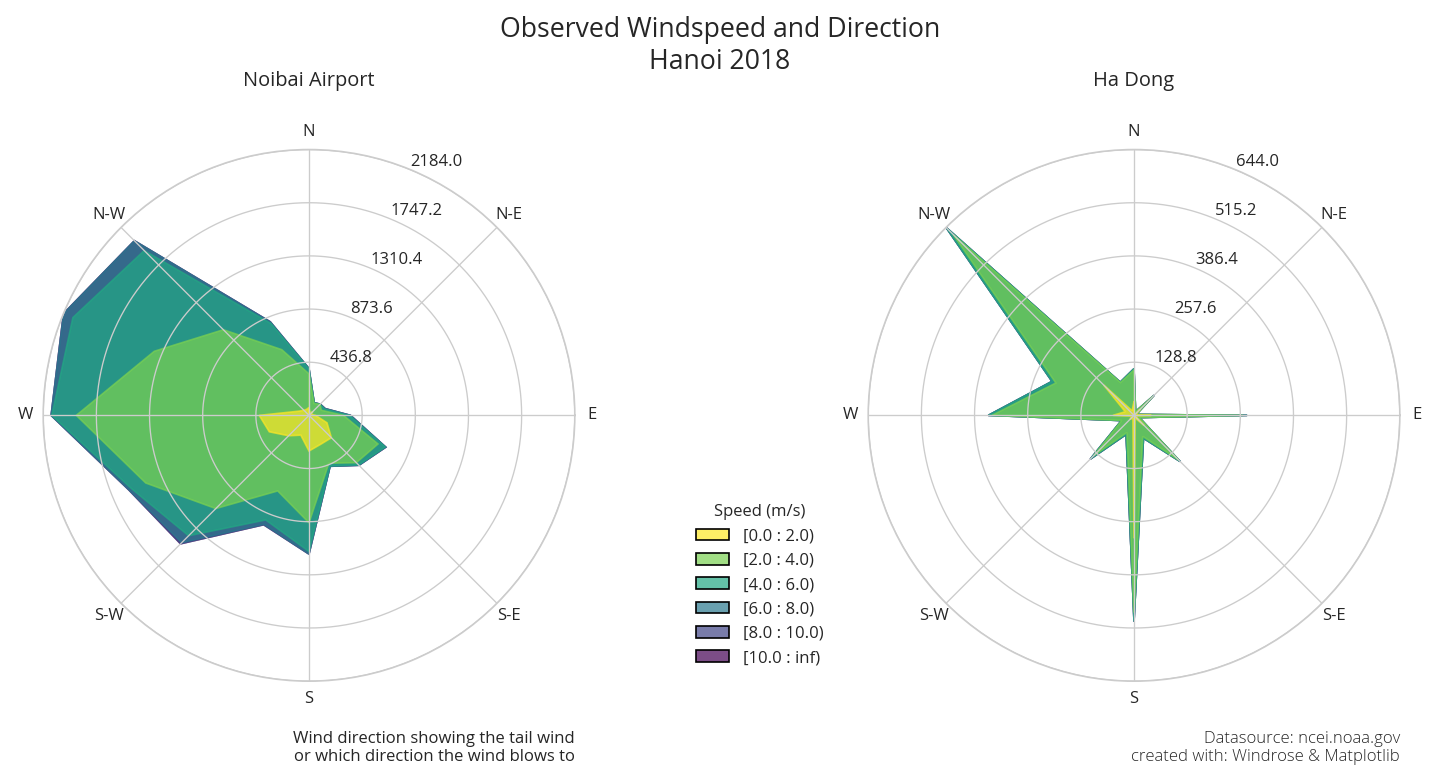
2.2 Correlation with wind and temperature (analysis)
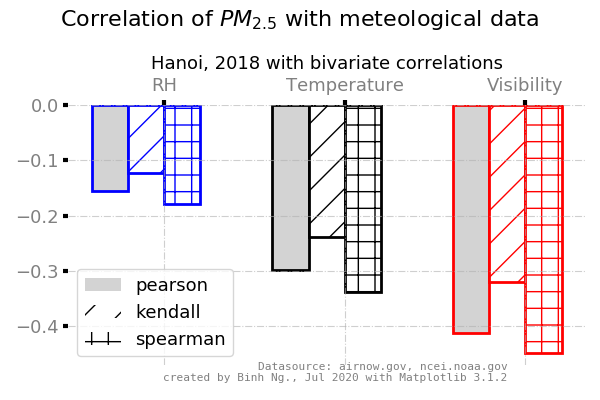
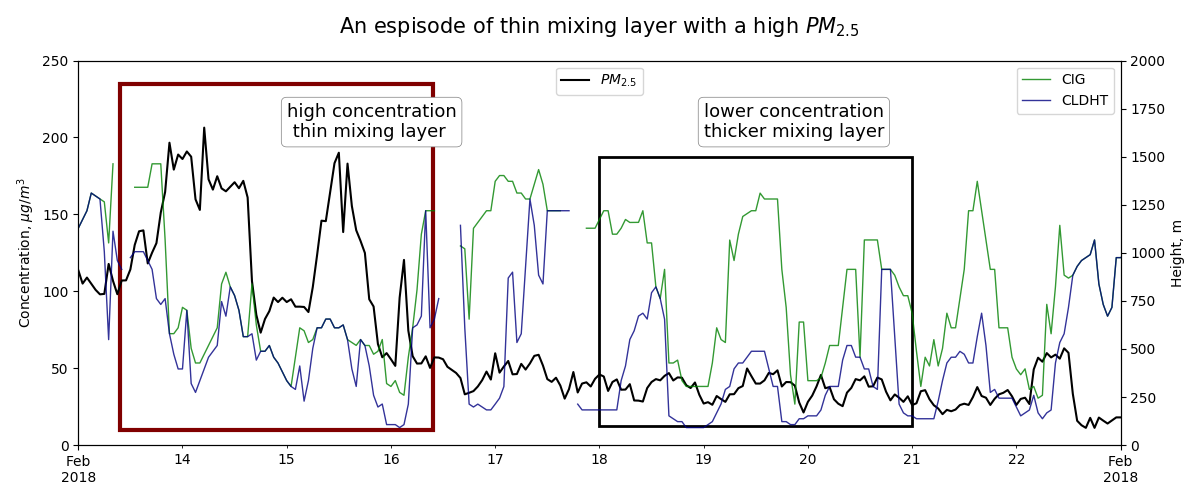
- explore correlation between meteorological paramters to observed PM2.5 concentration such wind, temperature, height above ground
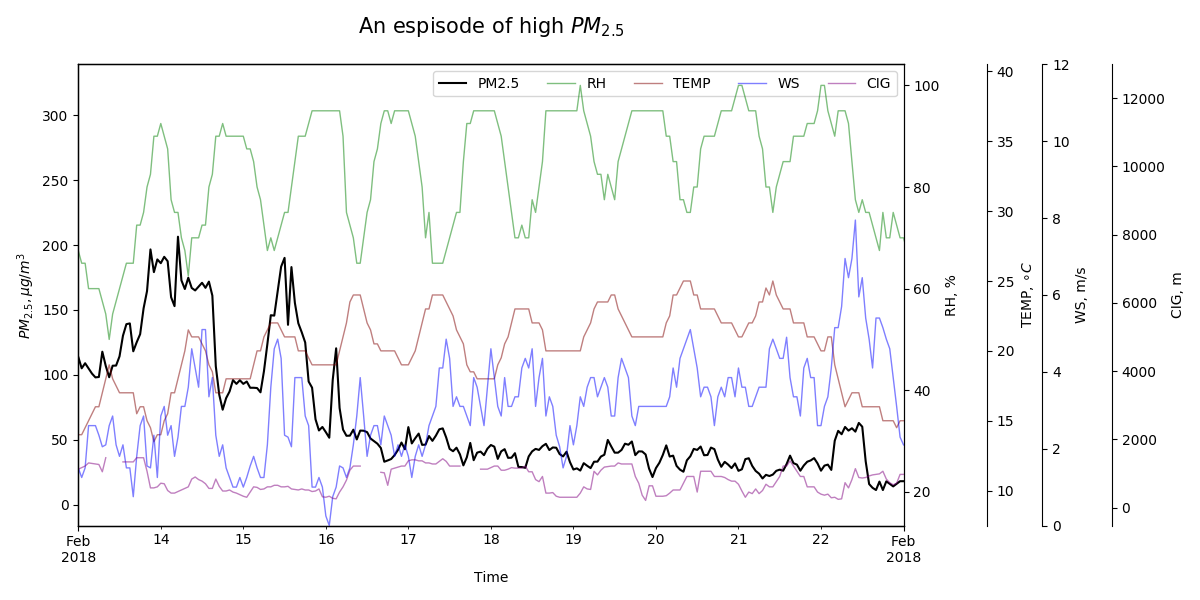
- capture espisode and examine relevant inputs with PM2.5
- some examples from this exercise
- correlation graph:
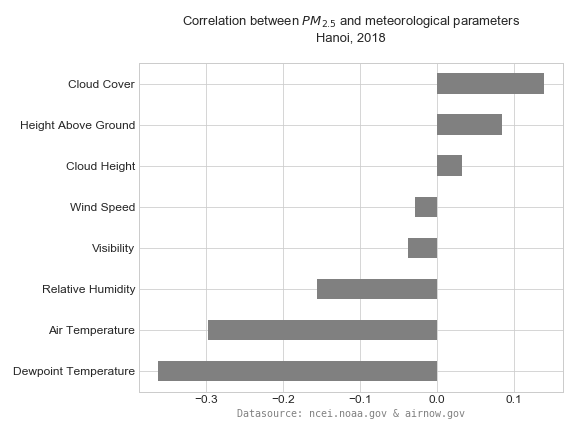
- work with MERRA-2 reanalysis data from NASA
- find the correlation from main groups (single level, surface turbulent flux, aerosols mixing ratio) and PM2.5
- here is the 3 summary graphs:
- Single level diagnosis
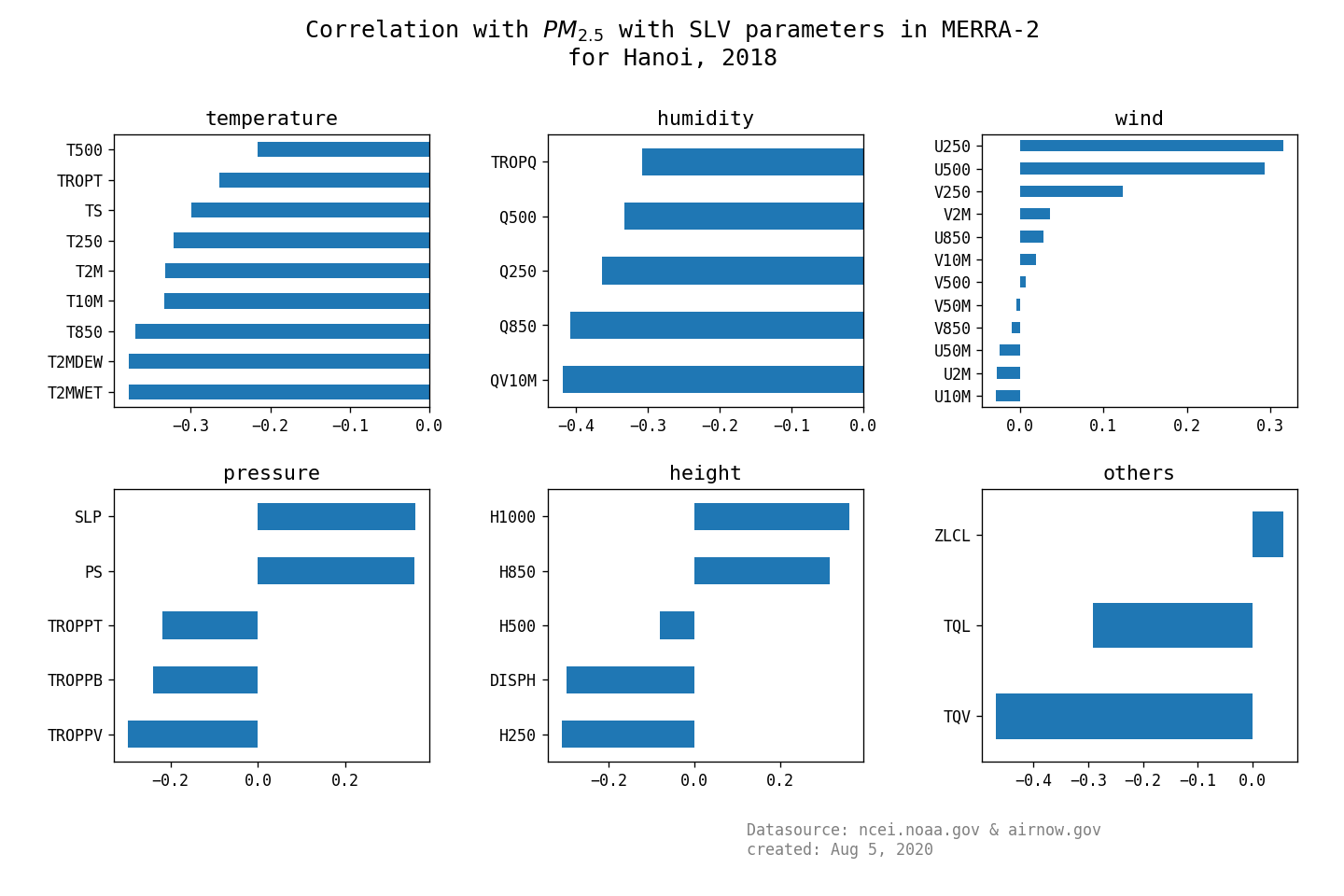
- surface turbulent flux
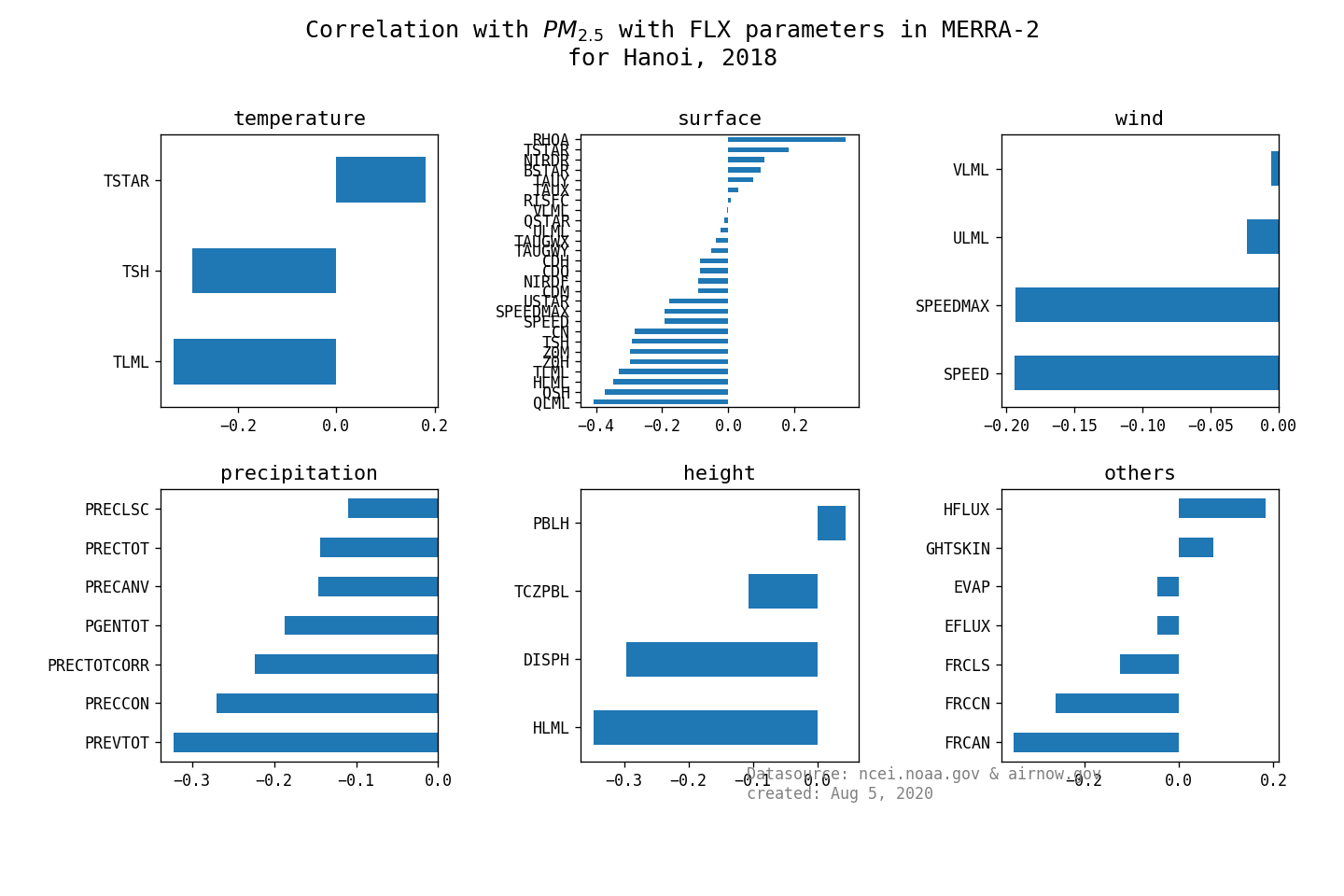
- Aerosol mixing:
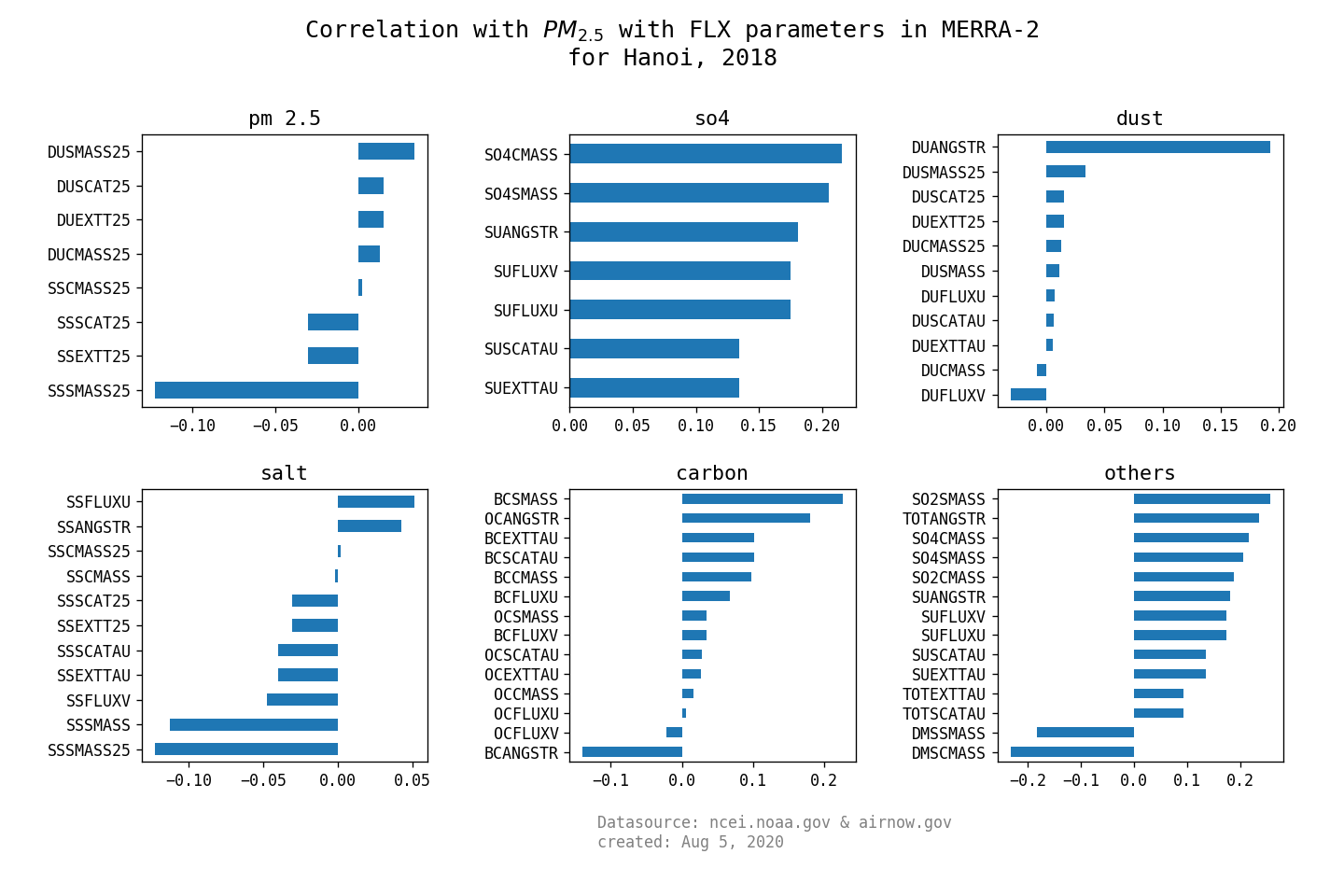
2.4 Conversion wind (U,V) component, RH from temperatures
- a detour to look at conversion of wind data (U, V) vectors to speed and direction in degree
- how to use MetPy packages calculate such conversion instead of manually undertake
- explore data for the next which is selecting relevant data for predicting PM2.5
- some graph examples:
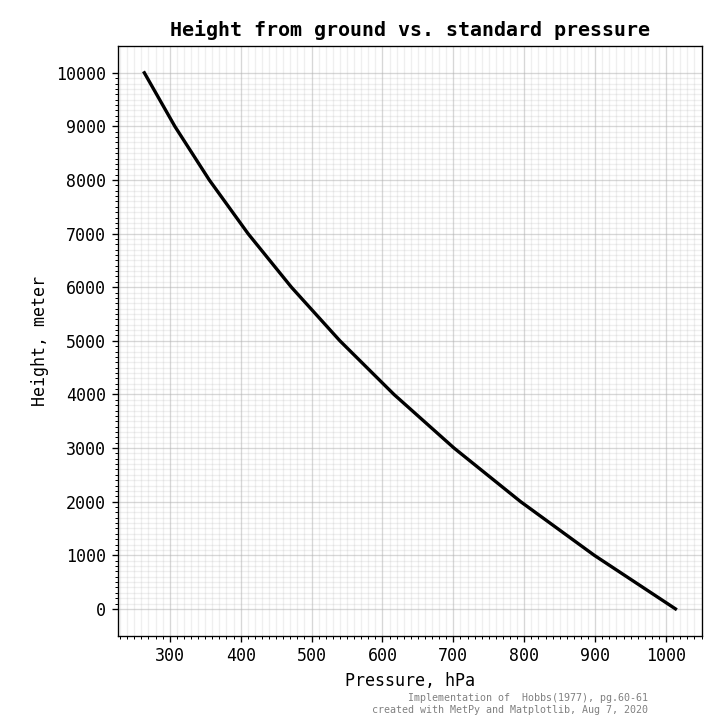
- relation of height (to the ground) vs. pressure
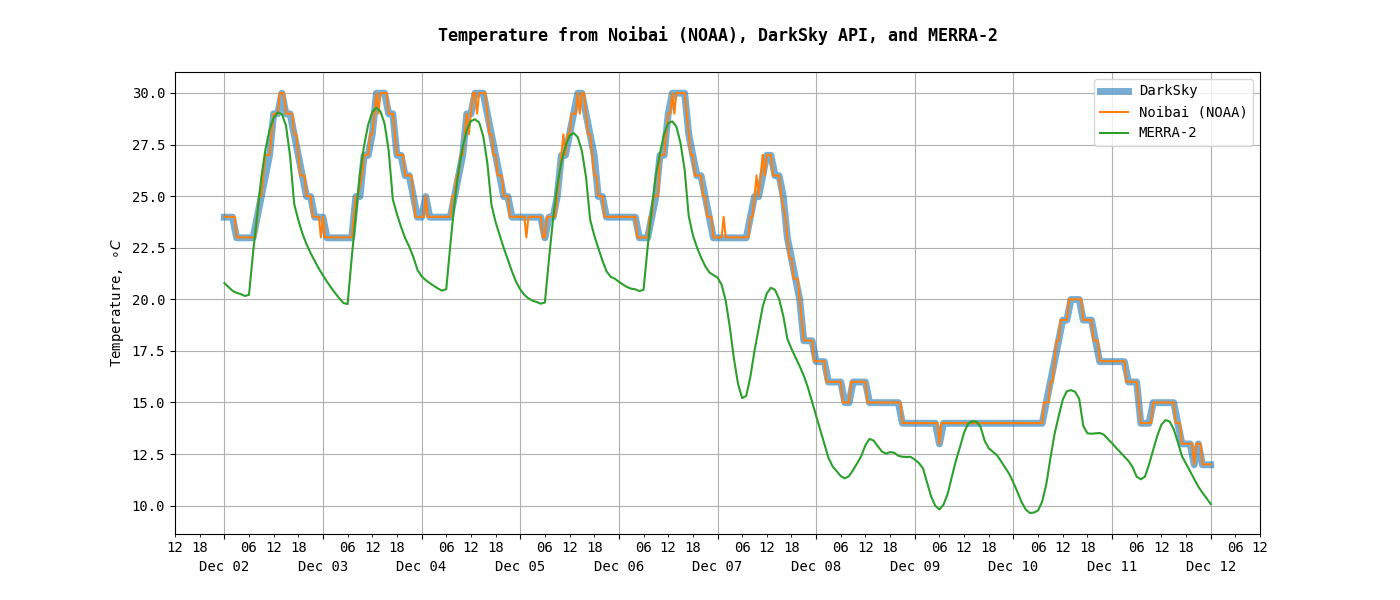
- compare values from different sources (such as from observed station, a public API, or reanalysis product)
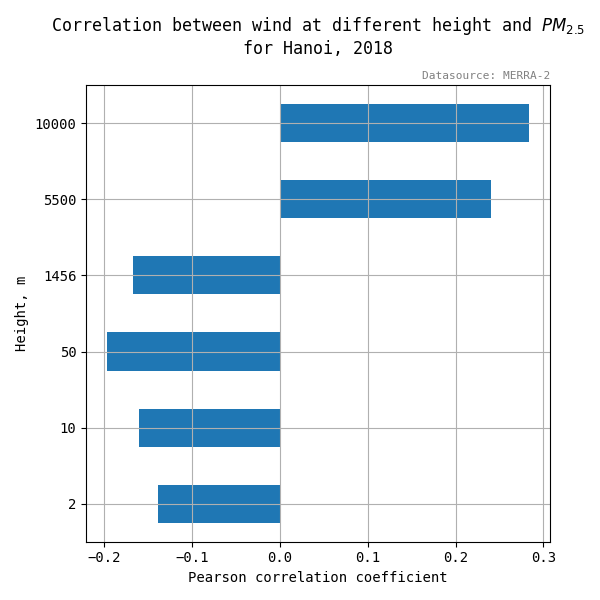
- correlation of wind speed in different altitude to PM2.5 concentration
3.1 Data selection
- combine three sources of data fromt the previous exercise
- PM2.5 from airnow.gov
- Ground observed data from ncei.noaa.gov
- Reanalysis data from MERRA-2 product, SLV and FLX groups (or tags)
- remove dependent data and data with weak (very weak) correlation with PM2.5
- here is outcome of this exercise:
- preliminary heatmap (of all most input parameters, don’t worry about the name just yet):
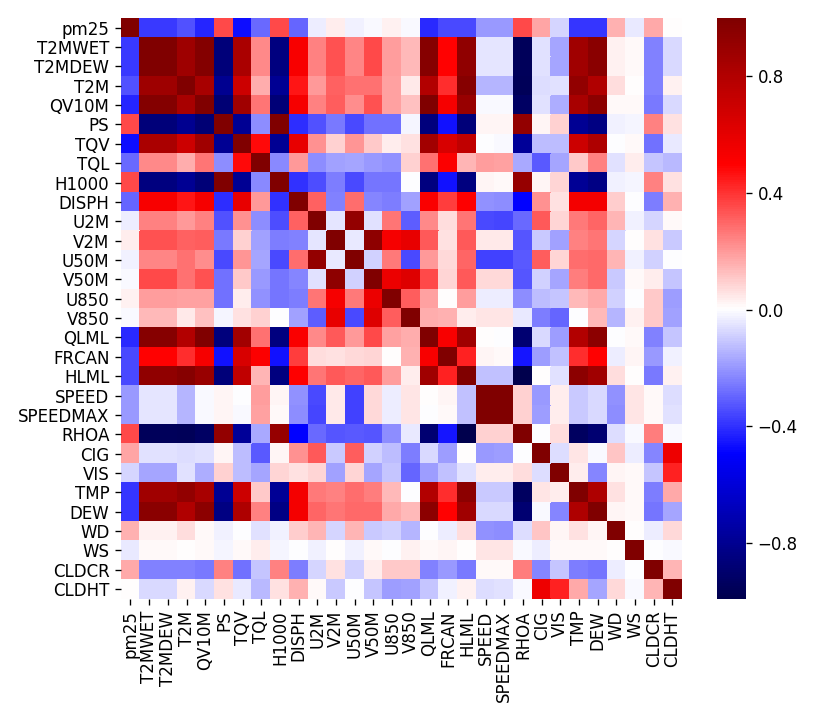
- a final version of selected data with correlation with PM2.5
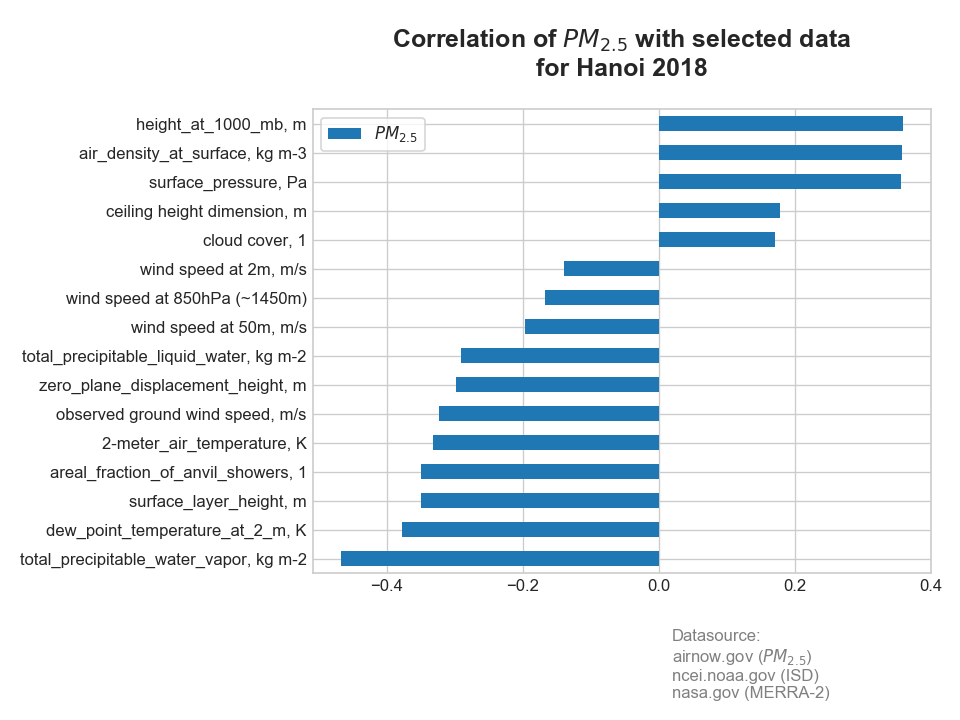
- and if you are curious about the full name of each parameter, here it is. Note that in the final version of CSV data, all temperature was converted from Kelvin (K) to Celsius (C).
{'TQV': 'total_precipitable_water_vapor, kg m-2', 'T2MDEW': 'dew_point_temperature_at_2_m, K', 'HLML': 'surface_layer_height, m', 'FRCAN': 'areal_fraction_of_anvil_showers, 1', 'T2M': '2-meter_air_temperature, K', 'WS': 'observed ground wind speed, m/s', 'DISPH': 'zero_plane_displacement_height, m', 'TQL': 'total_precipitable_liquid_water, kg m-2', 'v_50m': 'wind speed at 50m, m/s', 'v_850': 'wind speed at 850hPa (~1450m)', 'v_2m': 'wind speed at 2m, m/s', 'CLDCR': 'cloud cover, 1', 'CIG': 'ceiling height dimension, m', 'PS': 'surface_pressure, Pa', 'RHOA': 'air_density_at_surface, kg m-3', 'H1000': 'height_at_1000_mb, m'}3.1 Regression
- preliminary heatmap (of all most input parameters, don’t worry about the name just yet):
- Work with
Scikit-learnlibrary with regression models such Linear, DecisionTree, RandomForest - Evaluate performance of each model and an ensamble by PM2.5 and meteorological data for Hanoi, 2018. Datasets are cleaned and reduced from the previous excercise
- Apply a model with less feastures (DarkSky), but easiler to extract via API.
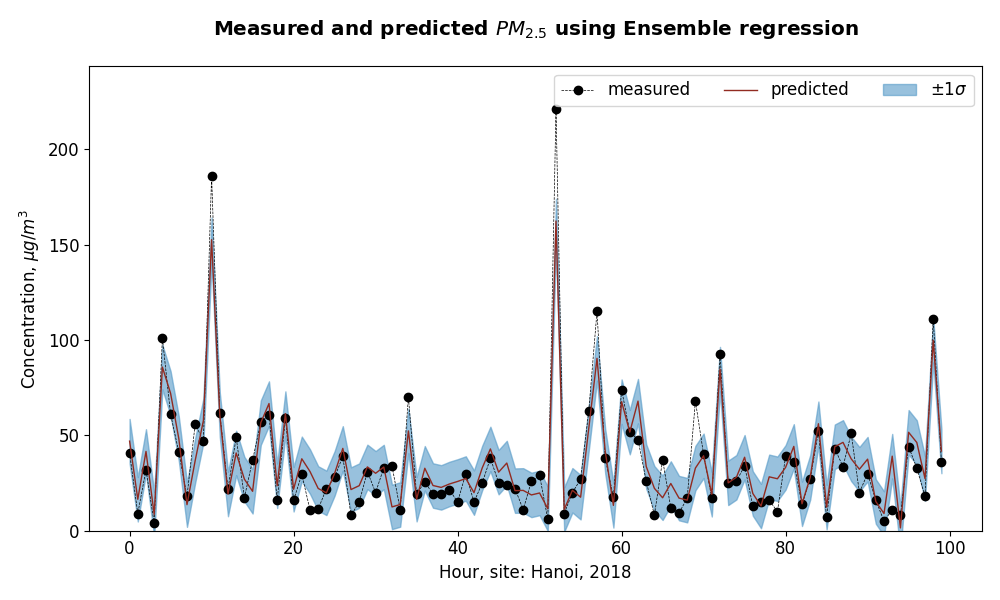
- Graphs from this excercise:
- perfomance on train dataset (using ensemble regression)
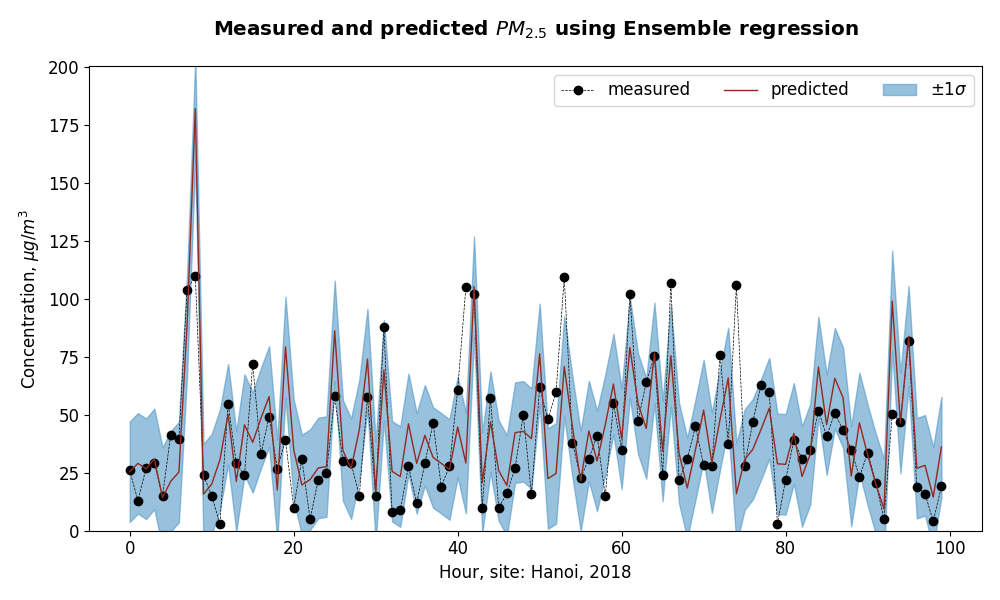
- performance on test dataset
- relative standard deviation on each model (lower is better)
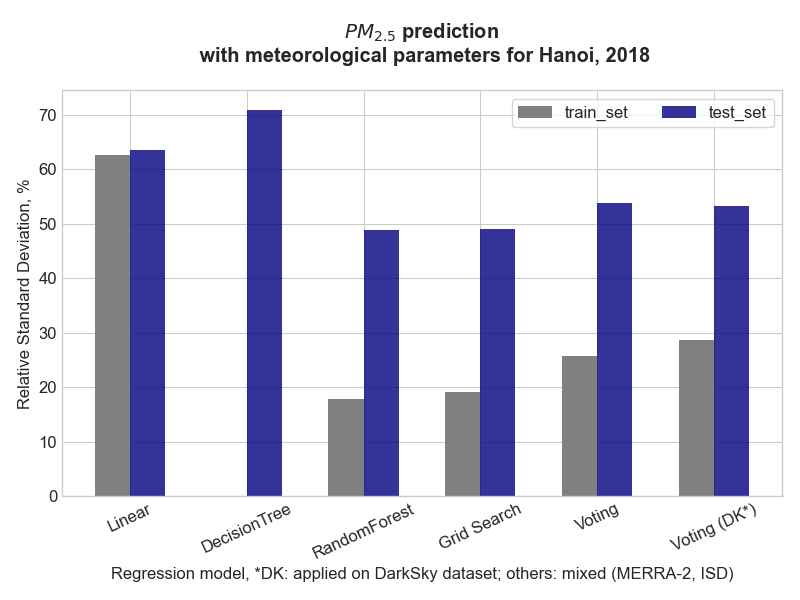
- perfomance on train dataset (using ensemble regression)
- an hourly update web-interface using the same concept can be found here with selected sites at my personal website b-io.info
- screenshot example:
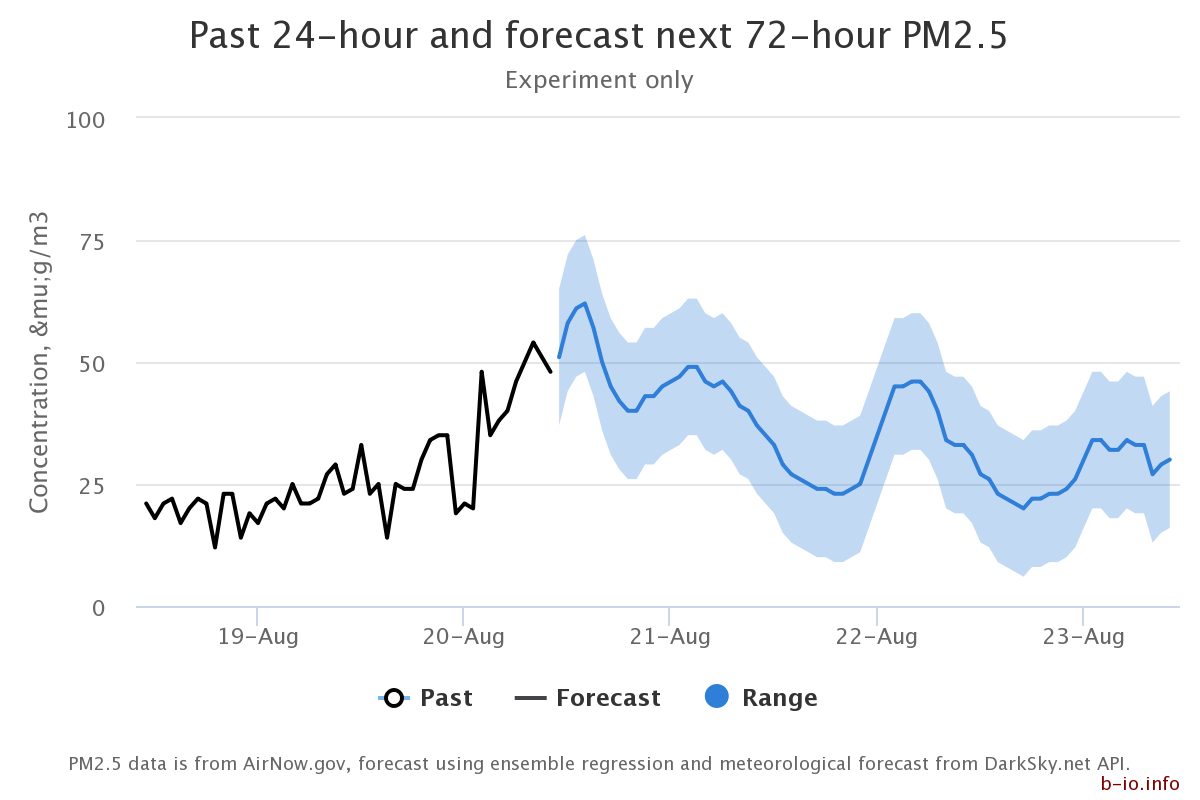
tools and packages
- the analysis is carried out on Jupyter Notebook (and later with Jupyter Lab 2.2), Ubuntu 18.04LTS.
- Python (3.6.9)
- Matplotlib (3.1.2)
- pandas (1.1.0)
- Seaborn (0.9.0)
- windrose (N/A)
- MetPy (1.0.0)
- scikit-learn (sklearn - 0.22.1)
- scipy (1.4.1)
Credits:
- some of the writing and coding are carried out while I were working with PAM Air project. I appreciate the flexiblity from the management so that I can make this happen.
- Books:
- Tutorials:
If this work is helpful to your research
- Admittedly, citing Github repository or other open project is new, but if this work is helpful for your work, I would appreciate the attribution, a link or a word.
- To cite this work, use this
Binh Nguyen, Air Quality Analysis, GitHub repository: https://github.com/binh-bk/air-quality-analysis
TODO
Keras (with TensorFlow)
- experiment with LSTM is not yet promising.